




This is the first in a series of articles examining what we call the two-trillion-dollar problem of the AI era: an unprecedented investment in AI infrastructure that is racing ahead of the revenue models and investment theses required to sustain it. While much of the public conversation has focused on models and consumer or engineering applications, this series asks a more fundamental question: Where, exactly, will the durable enterprise revenues of the AI age come from, and which layers of the stack are capable of absorbing the cost of intelligence at scale?
Part 1: The Infrastructure Supercycle
The Largest Buildout since the Cloud, and Why its Assumptions Are Being Challenged
Economic historians have long observed that infrastructure arrives before its economic logic is fully understood. Canals were dug before trade routes stabilized, railways were laid before demand justified them, and electricity grids were built before productivity gains could be measured.
Today, we are in the early stages of one of the largest infrastructure buildouts in modern economic history. Not since electrification, and not even since the rise of cloud computing, has so much capital been committed so quickly to a single technological substrate. Artificial intelligence is the driver. But unlike previous technology breakthroughs, this one reveals a deeper tension: the economic assumptions that once governed large-scale computing are beginning to fail just as investment accelerates.
Over the next five to seven years, global spending on AI-related infrastructure is expected to break records. According to some sources, OpenAI itself committed to $1.4T in deals to build 30GW of compute and data centers by the end of the decade, supported by long-term infrastructure and power commitments that could exceed $2 trillion in cumulative capital and operating expenditure over time (while other recent reports quoted a revised commitment of $600B). This includes not only servers and chips, but land, cooling systems, networking equipment, and power infrastructure.
This acceleration is driven by adoption rates which have already reached historic scale, but every marginal increase in usage translates into real-time increases in inference load, power consumption, and hardware utilization. According to its January 2026 business update, OpenAI scaled its power consumption from approximately 0.2 GW in 2023 to nearly 2 GW in 2025 (which is roughly the average electricity consumption of 2 million people, 24/7, averaged across a year), while revenue scaled from roughly $2B ARR to over $20B over the same period. Compute scaled nearly tenfold. Revenue scaled roughly tenfold. The variable that did not decouple was cost.
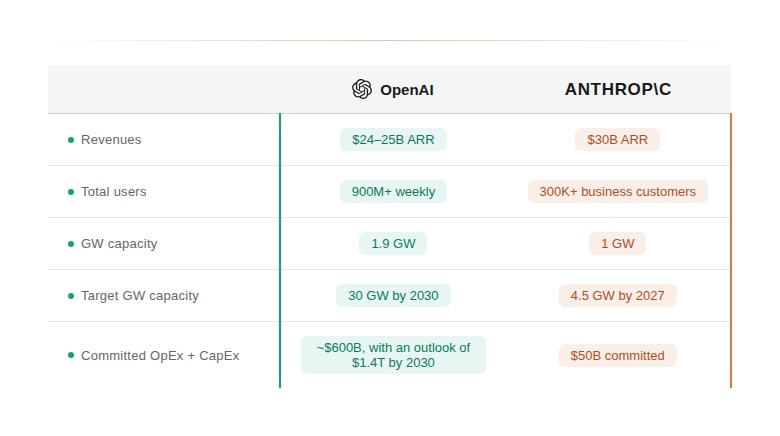
It matters because it marks a break from prior technology cycles.
For decades, the economics of computing benefited from an invisible subsidy: Moore’s Law. Performance improved predictably, costs declined, and infrastructure scaled efficiently. Software companies captured the majority of value because hardware efficiency improved in the background. But that dynamic no longer holds. While semiconductor innovation continues, it no longer offsets the scale of modern AI workloads. Compute requirements for training and serving frontier models are growing at well over 2x per year. As a result, the constraints governing AI infrastructure have shifted decisively from software economics to physical limits. Power density, heat dissipation, latency, and bandwidth now define what can be built, where it can be built, and at what cost. Energy systems, cooling technologies, and network architectures are no longer supporting layers, they are core determinants of scalability.
Crucially, this reintroduction of physics fundamentally alters the return profile of AI infrastructure.
In previous cycles, infrastructure costs were amortized over decades of improving unit economics. Today, capital costs are front-loaded, energy costs are persistent, and marginal efficiency gains are uncertain. The cost curve is steepening at precisely the moment when deployment and user adoption is accelerating. Which leads us to the central unresolved question of the AI economy: The 2 Trillions Dollars Problem.
At least $2T are being invested upfront in AI infrastructure whose marginal economics are deteriorating rather than improving. Yet the revenue pools required to justify this investment are not yet in sight.
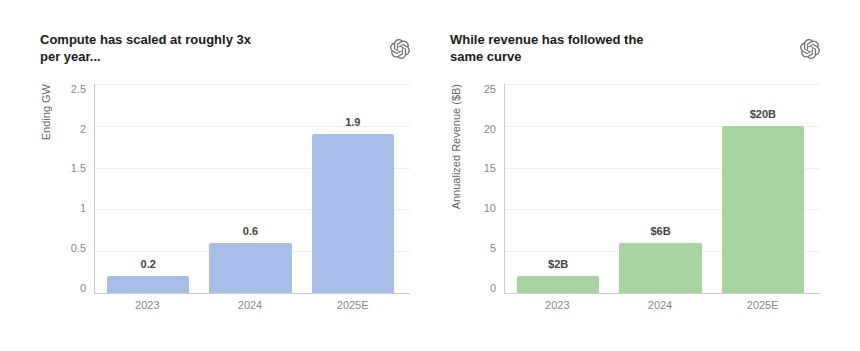
As illustrated above, consumer AI, despite explosive adoption, generates at least $70B revenues as of April 2026 (out of which $25B attributed top OpenAi and $30B to Anthropic, and assuming Gemini revenues are also in that range). Foundation models face growing commoditization and pricing pressure, limiting long-term margin capture. Foundation models face growing commoditization and pricing pressure. Model switching costs remain low, performance gaps narrow quickly, and customer churn increases as competing systems reach parity on quality and latency – the different AI models are interchangable, and aren’t sticky. The rapid improvement of alternatives such as Gemini or Claude underscores this dynamic: marginal gains in model capability are increasingly insufficient to lock in durable demand. As a result, even category leaders are forced to compete on price, bundles, and distribution rather than sustained technological separation.
Canals, railways, and electrical grids were expensive to build, but once constructed, their marginal cost of use declined steadily. Each additional unit of commerce, transport, or productivity made the system more efficient. Artificial intelligence inverts this logic. It is not only expensive to construct, it is persistently expensive to operate. Compute does not become meaningfully cheaper at the margin, energy consumption rises with use, and efficiency gains no longer offset scale. In effect, the AI era is the first major infrastructure cycle in which scale increases operating cost rather than reducing it. This asymmetry sits at the heart of the AI economic debate.
Ultimately, infrastructure of this scale requires a dominant and lucrative application layer capable of absorbing its cost and converting it into durable, high-margin revenue. In prior technological waves (such as in the cloud revolution), that role was played by enterprise software.
Whether AI can follow the same path or not is where the real debate begins. At Viola, we are cautiously optimistic. Despite the unprecedented scale of infrastructure investment, AI remains early in its diffusion curve: Microsoft’s Global AI Adoption 2025 report estimates that only around 16 percent of the global population has used generative AI to date, well below the penetration levels reached by the internet at comparable stages.
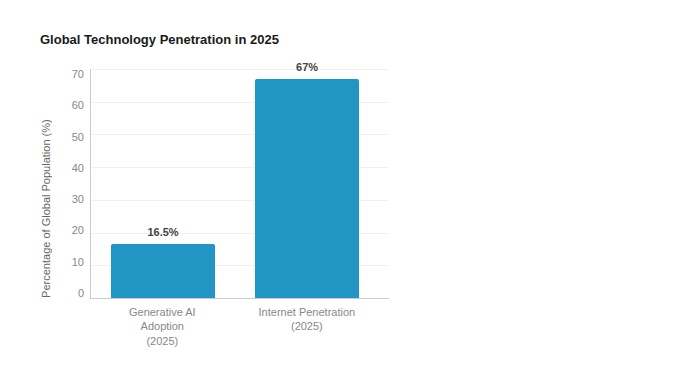
This gap suggests that the economic story of AI is far from written.
In the next article, we turn to the enterprise layer, breaking down the emerging AI stack across horizontal platforms and vertical systems to examine where durable revenues may ultimately take shape.
